FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems
MLSys 2026, 2026
Quick links:
- GitHub: https://github.com/flashinfer-ai/flashinfer-bench
- Webpage & Leaderboard: https://bench.flashinfer.ai/
- Dataset: https://huggingface.co/datasets/flashinfer-ai/flashinfer-trace
- Blog post: https://flashinfer.ai/2025/10/21/flashinfer-bench.html
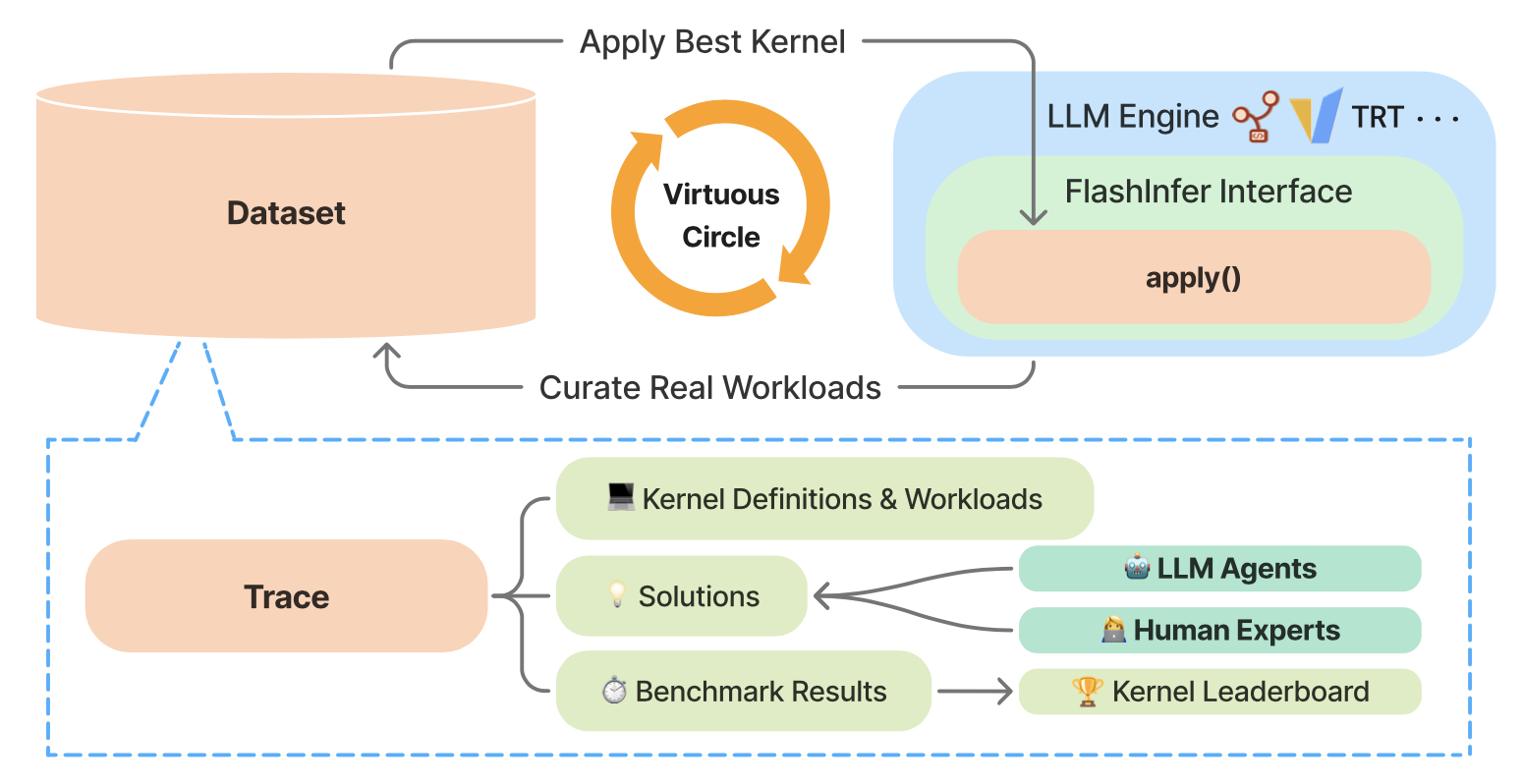
LLM agents are capable of generating GPU kernels, but integrating these AI-generated kernels into real-world inference systems is challenging.
FlashInfer-Bench addresses this gap by establishing a standardized, closed-loop framework that connects kernel generation, benchmarking, and deployment. It provides a unified schema describing kernel definitions, workloads, implementations, and evaluations, enabling consistent communication between agents and systems.
Built on real serving traces, FlashInfer-Bench includes
- a curated dataset, a robust correctness- and performance-aware benchmarking framework,
- a public leaderboard to track LLM agents’ GPU programming capabilities, and
- a dynamic substitution mechanism that seamlessly injects the best-performing kernels into production LLM engines such as SGLang and vLLM.
FlashInfer-Bench thus establishes a practical, reproducible pathway for continuously improving AI-generated kernels and deploying them into large-scale LLM inference.