
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
portfolio
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems
A standardized, closed-loop framework that connects kernel generation, benchmarking, and deployment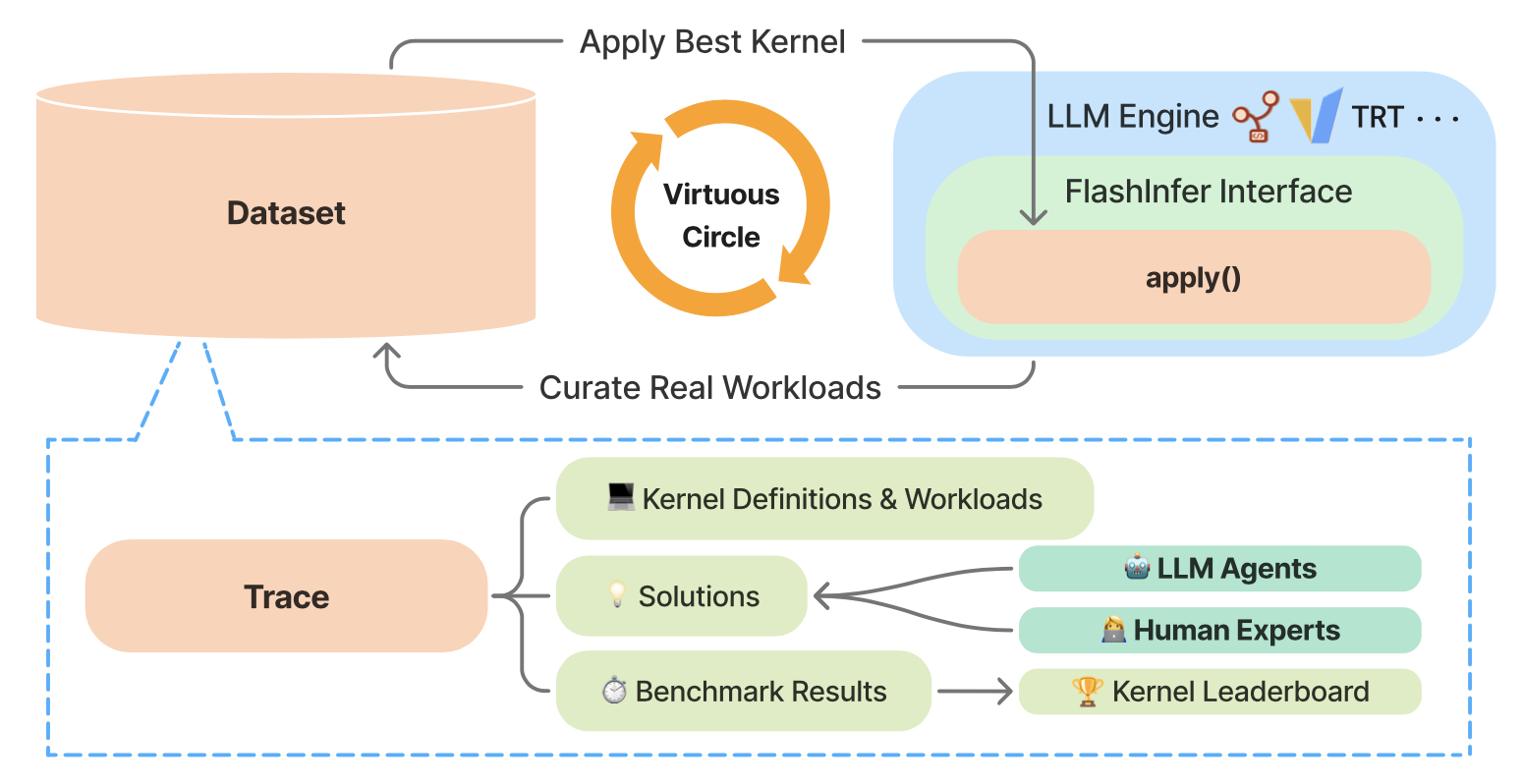
Nimbus: Burst-Resilient Hybrid Inference for LLMs
Routing algorithm for real-world LLM services—balancing TTFT SLOs and cost via selective API offload.
Clock2Q+: Correlation-Aware Metadata Caching Replacement Algorithm for Enterprise Storage Systems
Production-oriented cache replacement algorithm for VMware vSAN.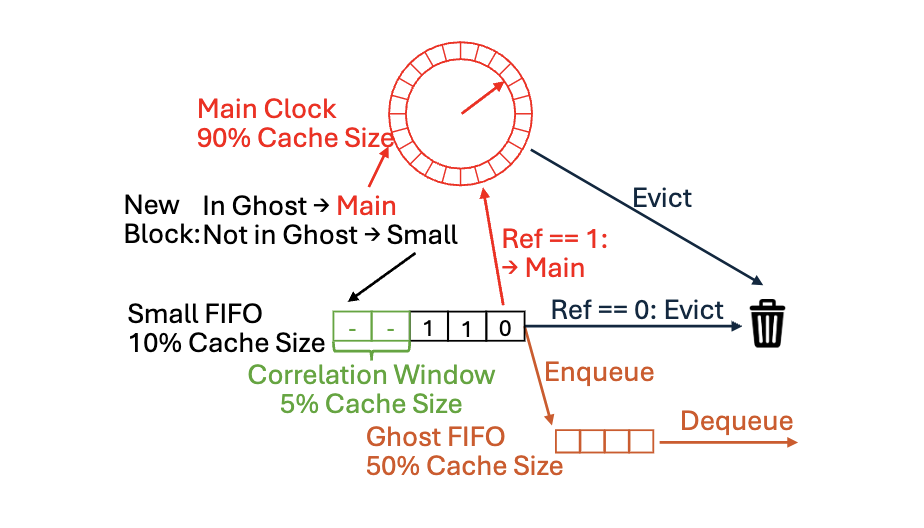
WebLLM Assistant: Browser Agents Powered by In-Browser LLMs
A middle-layer API that bridges local web agents with the browser environment; Overleaf & Google Workspace integrations.
publications
Token Prediction as Implicit Classification to Identify LLM-Generated Text
Published in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
This paper introduces a novel approach for identifying the possible large language models (LLMs) involved in text generation. Instead of adding an additional classification layer to a base LM, we reframe the classification task as a next-token prediction task and directly fine-tune the base LM to perform it. We utilize the Text-to-Text Transfer Transformer (T5) model as the backbone for our experiments. We compared our approach to the more direct approach of utilizing hidden states for classification. Evaluation shows the exceptional performance of our method in the text classification task, highlighting its simplicity and efficiency. Furthermore, interpretability studies on the features extracted by our model reveal its ability to differentiate distinctive writing styles among various LLMs even in the absence of an explicit classifier. We also collected a dataset named OpenLLMText, containing approximately 340k text samples from human and LLMs, including GPT3.5, PaLM, LLaMA, and GPT2.
WebLLM: A High-Performance In-Browser LLM Inference Engine
Published in arXiv, 2024
We introduce WebLLM, an open-source JavaScript framework that enables high-performance LLM inference entirely within web browsers. WebLLM provides an OpenAI-style API for seamless integration into web applications, and leverages WebGPU for efficient local GPU acceleration and WebAssembly for performant CPU computation. With machine learning compilers MLC-LLM and Apache TVM, WebLLM leverages optimized WebGPU kernels, overcoming the absence of performant WebGPU kernel libraries.
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
CMU 21-241 Teaching Assistant
Undergraduate level course, Carnegie Mellon University, Department of Mathematical Sciences, 2023
Matrices and Linear Transformations
CMU 10-605 Teaching Assistant
Graduate level course, Carnegie Mellon University, Machine Learning Department, 2024
Machine Learning with Large Datasets